取代Intel!NVIDIA數(shù)據(jù)中心專用處理器揭秘 一顆DPU頂替125顆x86 CPU,人工智能基礎(chǔ)軟件開(kāi)發(fā)的革命
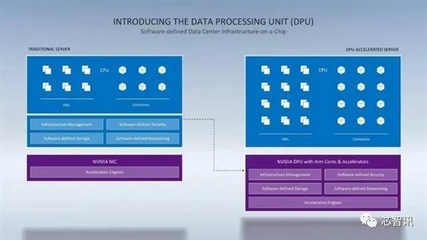
隨著人工智能、云計(jì)算和超大規(guī)模數(shù)據(jù)中心的迅猛發(fā)展,傳統(tǒng)的以CPU為中心的計(jì)算架構(gòu)正面臨前所未有的挑戰(zhàn)。在近期舉行的行業(yè)發(fā)布會(huì)上,NVIDIA高調(diào)揭曉了其專為數(shù)據(jù)中心設(shè)計(jì)的處理器——DPU(Data Processing Unit,數(shù)據(jù)處理器),并宣稱一顆DPU在某些場(chǎng)景下可以替代多達(dá)125顆傳統(tǒng)的x86 CPU。這一宣言不僅在半導(dǎo)體和云計(jì)算領(lǐng)域投下了一枚震撼彈,更預(yù)示著人工智能基礎(chǔ)軟件開(kāi)發(fā)模式將迎來(lái)一場(chǎng)根本性的變革。
DPU并非一個(gè)全新的概念,但NVIDIA憑借其在GPU領(lǐng)域的深厚積累,賦予了它前所未有的性能與使命。簡(jiǎn)而言之,DPU是一種高度專業(yè)化的處理器,旨在卸載、加速和隔離數(shù)據(jù)中心基礎(chǔ)設(shè)施任務(wù),如網(wǎng)絡(luò)、存儲(chǔ)、安全和虛擬化管理。傳統(tǒng)上,這些任務(wù)由運(yùn)行在通用x86 CPU上的軟件處理,消耗了大量寶貴的計(jì)算資源,而這些資源本應(yīng)用于運(yùn)行核心業(yè)務(wù)應(yīng)用和人工智能模型訓(xùn)練。
DPU的核心優(yōu)勢(shì):為何能“以一當(dāng)百”?
NVIDIA聲稱一顆DPU能頂替125顆x86 CPU,其底氣來(lái)源于DPU的專用化設(shè)計(jì)。
- 硬件卸載與加速:DPU集成了高性能的Arm CPU核心、強(qiáng)大的網(wǎng)絡(luò)接口(支持超高速以太網(wǎng)和InfiniBand)以及專用的可編程加速引擎。它能夠?qū)⒕W(wǎng)絡(luò)數(shù)據(jù)包處理、存儲(chǔ)虛擬化、加密解密、防火墻規(guī)則執(zhí)行等任務(wù)從主機(jī)CPU上完全“卸載”到自身硬件中,并以接近線速的效率執(zhí)行。這極大地釋放了主機(jī)CPU的算力。
- 超高的能效比:專用集成電路(ASIC)和針對(duì)特定工作負(fù)載優(yōu)化的架構(gòu),使得DPU在處理基礎(chǔ)設(shè)施任務(wù)時(shí),其性能和能效遠(yuǎn)超通用CPU。在數(shù)據(jù)中心規(guī)模下,這意味著巨大的電力節(jié)省和碳排放降低。
- 增強(qiáng)的安全性與隔離性:DPU可以在硬件層面創(chuàng)建“零信任”安全模型。它能夠管理數(shù)據(jù)中心的“根安全”,將管理控制面與用戶應(yīng)用數(shù)據(jù)面嚴(yán)格隔離,即使主機(jī)系統(tǒng)被攻破,基礎(chǔ)設(shè)施本身也能受到保護(hù)。
對(duì)人工智能基礎(chǔ)軟件開(kāi)發(fā)的深遠(yuǎn)影響
DPU的普及將深刻重塑人工智能基礎(chǔ)軟件的開(kāi)發(fā)、部署和運(yùn)行方式。
- 釋放AI算力瓶頸:在AI訓(xùn)練和推理集群中,CPU常常成為瓶頸,忙于處理數(shù)據(jù)移動(dòng)、通信同步(如NVIDIA的NCCL庫(kù)操作)和存儲(chǔ)I/O,而非專注于計(jì)算。通過(guò)DPU卸載這些任務(wù),GPU和AI加速器可以獲得近乎100%的專注時(shí)間用于矩陣運(yùn)算,大幅提升整個(gè)AI工作流的吞吐量和效率。開(kāi)發(fā)者可以更專注于算法創(chuàng)新,而無(wú)需過(guò)度優(yōu)化底層數(shù)據(jù)流。
- 重新定義軟件棧架構(gòu):未來(lái)的數(shù)據(jù)中心軟件棧將演變?yōu)椤癈PU+GPU+DPU”的三核驅(qū)動(dòng)架構(gòu)。系統(tǒng)軟件、云計(jì)算平臺(tái)(如OpenStack、Kubernetes)和存儲(chǔ)系統(tǒng)(如Ceph)將進(jìn)行深度重構(gòu),以利用DPU的硬件加速能力。例如,虛擬機(jī)的熱遷移、網(wǎng)絡(luò)功能虛擬化(NFV)、分布式存儲(chǔ)的元數(shù)據(jù)管理等關(guān)鍵操作,性能將得到數(shù)量級(jí)的提升。對(duì)于AI開(kāi)發(fā)者而言,這意味著更穩(wěn)定、低延遲和高帶寬的數(shù)據(jù)供給管道。
- 催生新的開(kāi)發(fā)范式與工具鏈:NVIDIA提供了名為DOCA(Data Center Infrastructure-on-a-Chip Architecture)的軟件開(kāi)發(fā)套件。DOCA類似于CUDA之于GPU,它允許開(kāi)發(fā)者利用標(biāo)準(zhǔn)的API對(duì)DPU進(jìn)行編程,輕松調(diào)用其硬件加速功能。這使得網(wǎng)絡(luò)、安全和存儲(chǔ)工程師能夠像AI科學(xué)家使用CUDA那樣,高效地開(kāi)發(fā)高性能、可擴(kuò)展的數(shù)據(jù)中心基礎(chǔ)設(shè)施應(yīng)用。人工智能基礎(chǔ)軟件與基礎(chǔ)設(shè)施軟件之間的界限將變得模糊,協(xié)同優(yōu)化成為可能。
- 推動(dòng)超融合與邊緣AI:DPU強(qiáng)大的集成能力使得在單臺(tái)服務(wù)器內(nèi)實(shí)現(xiàn)超融合基礎(chǔ)設(shè)施(HCI)變得更加高效和經(jīng)濟(jì)。對(duì)于邊緣AI場(chǎng)景,DPU可以幫助在資源受限的環(huán)境中,更安全、高效地處理數(shù)據(jù)流,為邊緣服務(wù)器提供企業(yè)級(jí)的數(shù)據(jù)中心能力。
挑戰(zhàn)與展望
盡管前景廣闊,DPU的普及仍面臨挑戰(zhàn)。生態(tài)系統(tǒng)的構(gòu)建是關(guān)鍵,需要整個(gè)軟件行業(yè),特別是操作系統(tǒng)、虛擬化平臺(tái)和云服務(wù)商的廣泛支持。開(kāi)發(fā)人員需要學(xué)習(xí)新的編程模型(如DOCA)。從市場(chǎng)格局看,NVIDIA此舉直接挑戰(zhàn)了以Intel為代表的傳統(tǒng)數(shù)據(jù)中心CPU霸主地位,Intel也通過(guò)IPU(Infrastructure Processing Unit)等產(chǎn)品進(jìn)行回應(yīng),未來(lái)的競(jìng)爭(zhēng)將異常激烈。
總而言之,NVIDIA DPU的推出不僅僅是發(fā)布了一款新芯片,更是吹響了數(shù)據(jù)中心計(jì)算架構(gòu)從“以CPU為中心”向“以數(shù)據(jù)為中心”全面轉(zhuǎn)型的號(hào)角。對(duì)于人工智能領(lǐng)域而言,這意味著底層基礎(chǔ)設(shè)施將變得更加強(qiáng)大、智能和透明,為下一個(gè)萬(wàn)億參數(shù)級(jí)別的AI模型和更復(fù)雜的AI應(yīng)用,鋪平了堅(jiān)實(shí)的硬件與軟件基礎(chǔ)。一顆DPU替代125顆CPU的故事,正是這場(chǎng)靜默革命中最響亮的開(kāi)場(chǎng)宣言。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.xinanzl.cn/product/48.html
更新時(shí)間:2026-01-19 05:53:35